This is a side project developped by David Serrault. UX design director, fascinated by the potential of artificial intelligence and the challenges it poses to our practices. So far, the images have been generated using Midjourney versions 4 and 5.1. This website has been developped with the support of ChatGPT4.
A methodical exploration of the "latent space"
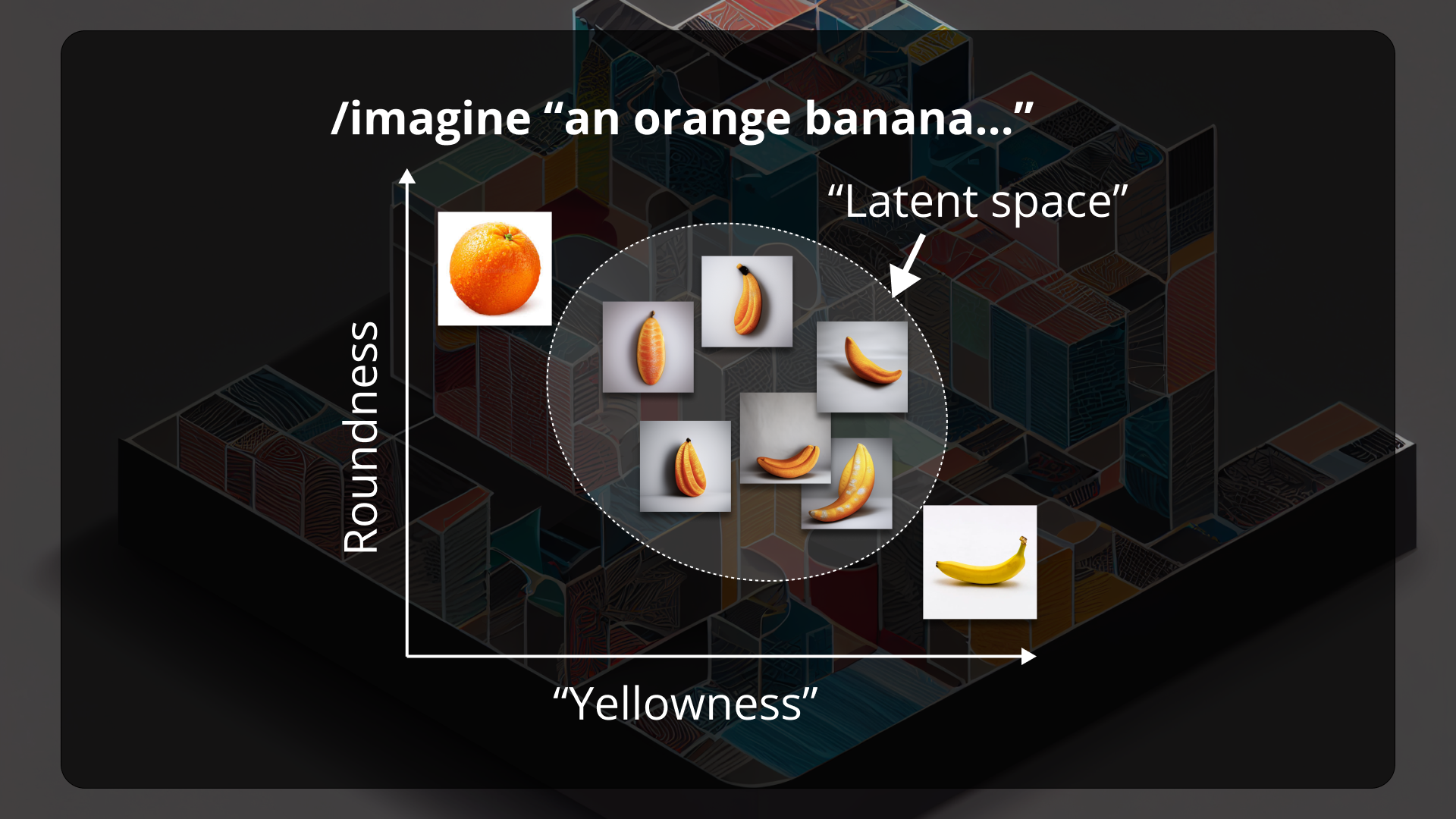
Contrary to a common idea, text-to-image generative models do not store the image sets used for their training, but rather store their visual characteristics as vectors.
The concept of the latent space in the field of text-to-image generative models refers to a lower-dimensional vector space that represents the visual characteristics of images generated from input text.
In these models, a generator neural network takes a sequence of words as input and produces a corresponding image as output. The latent space is where the generator stores the learned representation of the input and output data, capturing the essential visual features of the images.
The term "latent" refers to the fact that these visual features are not directly observable, but rather inferred from the input text. Through an unsupervised learning process called training, the generator network is trained on a large dataset of text-image pairs, learning to map input text to corresponding output images by exploring the latent space. Once the model is trained, it can generate new images by sampling from the latent space.
The latent space contains virtually all possible images located at the intersections of all the words that can be provided as input into the prompts. This is a vast and fascinating territory. Through a methodical exploration, we may discover original ways to represent words or concepts.
En bref :